Git Workflow : bonnes pratiques pour vos projets
De nos jours se lancer dans un projet sans outil de versionning est proche d’une folie. Toutefois ces outils ne sont pas toujours utilisé de manière optimale. Je vais donc présenter dans cet article une sorte de workflow que nous pouvons mettre en place avec un projet versionné par exemple sur github.
Présentation générale :
Pour ce ne connaissant pas git, il s’agit d’une solution permettant de versionner du code. Ainsi l’on a accès a toute les modifications ayant été faite sur le code. On peut donc aisément revenir en arrière etc.
Les forks
Chaque projet sur github est hébergé en dans un dépôt, lorsque vous voulez avoir votre version vous pouvez soit :
- Copier le contenu (zip) dans un nouveau dépôt – on perds alors la dépendance avec le projet initial
- Faire une copie qui est toujours relié au dépôt d’origine : on parle de fork.
C’est grâce a ce lien que l’on peut proposer ses modifications. Ceci est possible en utilisant le mécanisme de pull request que nous allons expliquer un peu plus bas.
Il est important de noter que si vous faites un fork d’un dépôt privé et que l’on vous retire les droits de lecture sur le dépôt d’origine, votre fork disparaîtra obligatoirement.
Nos aurons donc trois principaux dépôt qu’il faudra prendre en compte :
- le dépôt local (physique sur la machine)
- le dépôt distant (on le nommera origin)
- le dépôt distant d’origine (on le nommera upstream)
L’un des principaux avantage à l’utilisation des fork est que chaque développeur possède a la fois un dépôt local et distant qui lui sont dédié – ses modifications n’impacte que lui. Le troisième sert juste de base commune.
Les branches
Une vision simpliste est de s’imaginer un projet comme ayant une unique avancé. En réalité des fonctionnalités sont ajouté sur des version parallèle (sorte de copie n’affectant pas la version principale) avant d’être fusionné avec la base principale. On parle de branche – chaque branche est une évolution différente du projet qui peuvent s’éloigner mais aussi se rejoindre (on parle de merge).
Le nombre de branche varie totalement en fonction des projets, on retrouve généralement :
- La branche principale (codé utilisé en production) appelle master
- Une branche de développement
Il s’ajoute a ces branches quelquefois des branches dédié a l’étape de pre-prod et de test. Sur certain projet plus actif on a aussi une branche par fonctionnalité en cours de développement plutôt qu’une seule. Enfin des vieilles versions possède leurs propre branche – par exemple pour avoir toujours des mise a jour de sécurité.
Afin de fusionner deux branches on utilise souvent le processus de merge. On fait un nouveau commit qui aura pour parent le dernier commit de chaque branche. A l’inverse on peu aussi utiliser le système de rebase qui lui prend les commit d’une branche et les “joue” a la suite de l’autre branche. 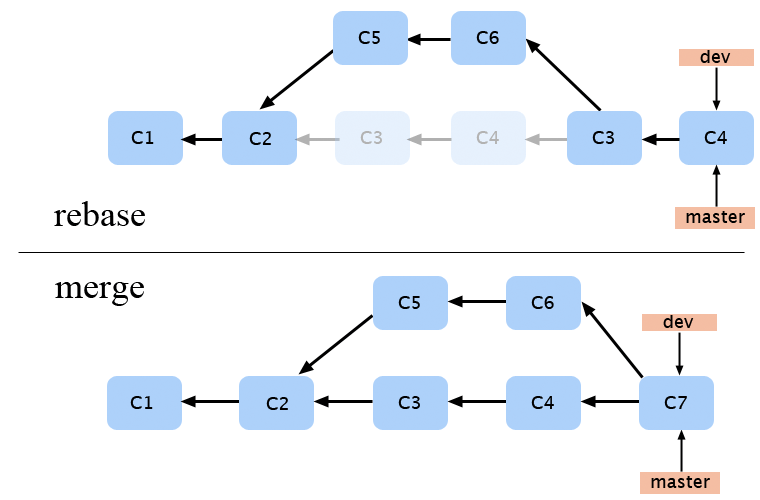
Personnellement je préfère utilisé les rebase pour deux raisons :
- on garde un historique linéaire
- la gestion de conflit étant commit par commit est relativement plus aisé
Pull Request :
Lorsque vous voulez que les modifications faites sur votre copie soient disponible pour tout le monde vous allez surement utiliser le principe de pull request. Vous choisissez une branche de votre distant, une du distant d’origine et proposez un merge entre les deux. Les personnes ayant les droits d’écriture sur le dépôt d’origine peuvent accepter votre pull request ou vous demandez de faire quelques modifications avant. Dans certains cas votre demande sera refusé et votre pull request sera fermé.
Quelques conseil pour avoir plus de chance de voir votre demande accepté :
- Respecter les normes du projet ( souvent dans le wiki ou un fichier CONTRIBUTING)
- Vérifier que les tests passent bien
- Pull le dépôt upstream sur votre branche avant – ca évitera d’avoir des conflits et voir votre pull request impossible a accepter
Votre code sera potentiellement critiqué, analysé etc, n’hésitez pas a vous justifier quand besoin et voyez y une chance de vous améliorer. En effet il y’a beaucoup a apprendre des diverses codes review que l’on peut avoir.
Les tags
La notion de branche ne suffit pas à définir un point particulier de l’évolution du code, on pourrait certes utiliser le numéro de commit mais il y’a un système bien plus pratique : les tags. Il s’agit de marqueur sur un état du code – a un commit bien précis. On peut se servir ce système comme systeme permettant de numéroter les versions. Cela à plusieurs avantages :
- On peut voir facilement la date de création de chaque version
- Idem pour les ajouts d’une version si la description est complète
- On peut aussi gérer facilement le choix de version avec des outils d’import de librairies (composer …)
- Si on utilise des numéro de version sémantique voir l’implication d’une mise a jour de version
Pour ceux n’étant pas au courant de ce qu’est un numéro de version sémantique il s’agit d’un numéro sous la forme de trois partie Major.Minor.Patch
Le patch est un fix sans problème d’incompatibilité
Le Minor est un ajout de fonctionnalité toujours sans incompatibilité
Le Major implique de grande modification avec de potentiel problème d’incompatibilité.
Vous pouvez avoir plus d’information sur ce site Gestion sémantique de version
WebHook et deploy key
Il s’agit la plus de fonctionnalités supplémentaires que l’on retrouve sur de nombreux service (github, bitbucket, gitlab etc).
Le webhook sont des appels fait lors d’interaction spécifique, par exemple a chaque commit, pull request etc un appel est fait a un service externe qui pourra par exemple exécuter les tests. Ceci permet de faire des actions de manière automatique. La deploy key est comme son nom l’indique une clef qui sera utilisé pour le déploiement uniquement. Je m’explique cette clef ssh permet d’avoir un accès en lecture au dépôt ainsi le serveur possédant la clef privé associé pourra récupérer le code avec celle ci – les serveurs n’ont donc pas besoin de compte et peuvent quand même être identifié a l’aide de leurs clef. Ce système est utile quand le déploiement est automatisé et qu’aucun compte utilisateur ne pourra être utilisé.
Conclusion
Pour conclure nous allons voir un exemple ou l’ensemble des méthodes décrite ci-dessus sont assemblé pour former une procédure complete dans un projet.
Nous avons donc le projet dans son dépôt officiel, seul quelques personnes peuvent écrire sur ce dépôt – typiquement les core développeur (souvent le lead dev en entreprise). Le reste des développeur ont un accès en lecture. Il font donc un fork qui leurs permet d’avoir leurs copies. Ils peuvent donc travailler sur les mêmes branches – disons dev sans avoir d’interaction. Lorsque un développeur a fini sa tâche il récupère le code de la branche principale (dépôt officiel), ainsi son code aura déjà eu la résolution de conflit avant le pull request. Lors du pull request une analyse du code statique est lancé, de même pour les tests. Si tout ce passe bien les core développeur peuvent vérifier le code puis après modification potentielle accepter la pull request. Alors on pourra déployer de manière automatique le code – en effet les serveurs ayant le droit de lecture sur le dépôt peut récupérer le code source.
Bien que cet article peut sembler un peu long, je ne traite pas de la totalité des éléments que l’on pourrait incorporer dans un workflow centré sur git, n’hésitez pas a compléter ou poser vos questions en commentaire.
comments powered by Disqus